When the cloud doesn't work - privacy & agricultural information in the Farm Crap App
Posted Aug. 2, 2019 by Amber Griffiths and Dave GriffithsThe latest version of the Farm Crap App is currently undergoing final testing by agronomists and farmers before a new release in the autumn (let us know if you would like to take part in the beta testing). This version sees a gigantic increase in the amount of different crops and manures, with the vast majority of the RB209 guide represented. It is very satisfying to see this project become an officially recognised and government approved tool from its humble beginnings.
Previous versions of the Crap App were entirely self contained, with a simple option to email the information you recorded as a spreadsheet attachment for use outside the app. We have now added an ability to share farms and collaborate in groups collecting and recording data, merging the updates people make automatically. This works for a number of different situations - multiple people working together on larger farms as well as consultants working with multiple producers, who need a simple way to access to their records.
One of the activities built into this project from the start was a workshop in Cornwall with the people using the app to understand their needs and concerns, the limitations and opportunities they could see. We very much enjoy this way of co-creating things with people, as it means what we make is grounded and actually gets used in the end.
We had four questions to address with this workshop:
- How many different types of user of the Farm Crap App are there?
- Is there a need for an overview of the data which is different to the current app?
- Who has responsibility for data if it is stored centrally (e.g. GDPR) and does it need to be encrypted?
- Do we need to provide a system where users control their data rather than a central server?
The workshop consisted of roughly 15 people, including our collaborators at Duchy College and Rothamstead Research. We decided to break the workshop up into three sections, an introduction to the project and who we were, followed by a mapping exercise and a final sneak preview of the latest version for them to test.
We wanted to keep the mapping exercise quite open as the group was diverse, representing producers, advisors, contractors and associated industries. We used paper and string to provide a fully collaborative exercise taking up a large space, so everyone could easily contribute. We mapped the many different individuals, companies, government agencies and other organisations involved in handling farm data, and the various types and directions of data shared between them. This soon became extremely complex with lots of potential connections that the app could assist with. We spent the lunch break consolidating the map and looking for patterns, areas of common concern and came up with this very distilled version:
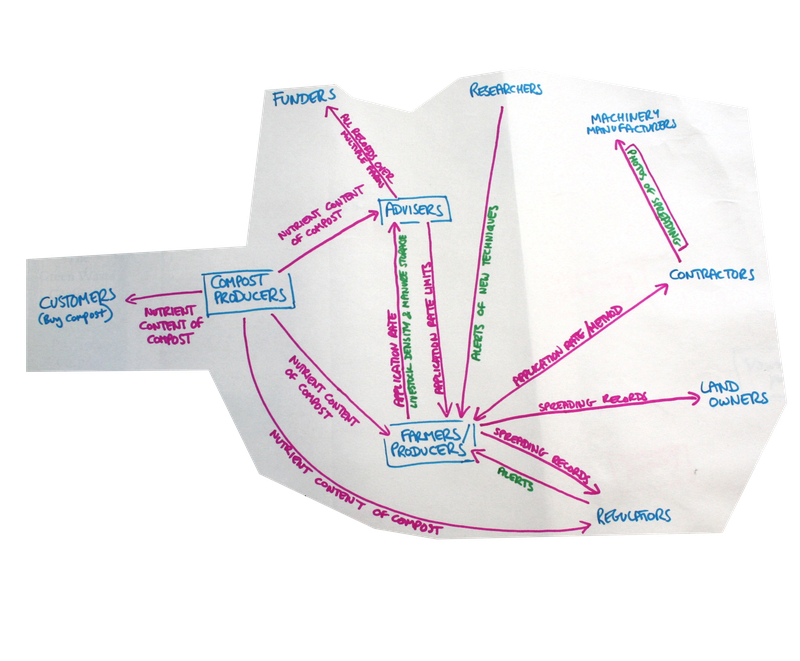
Agricultural information such as that collected by the Farm Crap App has financial ramifications for subsidy payments and so we were also concerned with who has liability for this information and how it should be stored. In order to answer these questions, we described five possible "sharing scenarios":
- Emailing a spreadsheet file containing the farm data
- Send your entire farm over email to someone else so they can load it into their Crap App
- Synchronise your farm info between devices (bluetooth or wifi-direct)
- Register and update via a central server controlled by Duchy College, data perhaps used for research purposes
- Register and update to a central server controlled by a government agency
Option 1 is what existed already, and options 4 and 5 are the standard "cloud" based ways of working. We originally expected to implement one of these two cloud server options, but mainly wanted to check if there was a difference in opinion based on who was running the service. There are already government agencies running cloud servers for this kind of data, so we thought it might be a situation they were used to.
The answers were surprisingly clear and strong - it turned out that using a cloud server was not going to be an option at all, regardless of who was running it. The problem is that if you are running a company advising farmers on their practices you have a responsibility for the information involved, as trust is a key factor when you are acting on behalf of a client. We talked a bit more about option 3, automatic synchronisation (this would be similar to Mongoose 2000) but it is important that the method of data transfer is easily understandable rather than happening as some kind of magic background activity - again control is the primary issue, along with keeping things as straightforward and familiar as possible.
It's important here to look at the bad things that could potentially happen with this kind of information. If a farmer is recording what nutrients they are putting into their soil, this can indicate that they have gone over some limits and can be fined (or lose out on a subsidy payment, which amounts to the same thing). It came across strongly that the communication with an advisor should not be considered in the same category as that with a government agency or a land owner. The advisor and producer need to be able to have a private conversation, with the freedom to record data which may not be correct or up to date, for example it may involve trying out different scenarios. If who has access to this communication feels unclear, it would impede the usefulness of the professional relationship.
The main issue with using a cloud server is that control of the data ultimately rests with the organisation paying for the disk space. A government agency will naturally use and observe any data uploaded to it. Even in the case of a university or private company - even if initially trusted, this relationship is one that needs to hold for ever, companies get bought by different shareholders with different aims, university research projects have end dates and researchers move on.
Technically we decided to implement a peer to peer scheme using normal email with attachments that are encrypted descriptions of the farm data. Using peer to peer communication, we are not storing information centrally anywhere - so liability for the data and GDPR are not an issue. We don't need to worry too much about security on the devices themselves (gaining access to someones phone to extract personal information is possible, but far too costly to be a realistic worry here) so the concern is mainly about preventing this data being casually readable as it passes from one device to another (which is all too commonly the case). The Farm Crap App uses "end to end" encryption, which means that even as developers of the app in question - we will never be able to access any farm data if we do not have the permission to do so.
We are using what is known as symmetric encryption, which means the same key is used to both encrypt and decrypt the data. This key is generated from a password the user enters when they export their farm data, they need to share this password with the other person they are sending the email to - who needs to enter it when they import. We used this class for Android and this one for iOS (in conjunction with the standard Apple libraries) that do a lot of the complex work for us, but we still had to understand what was going on to match the Apple and Android versions to talk to each other. One important detail is that we never persistently store either the password or key that's generated from it.
From a user point of view we tried to keep it as simple as we could, for example using the standard email systems on Android and iPhone to actually send the data - this is the Android export process:
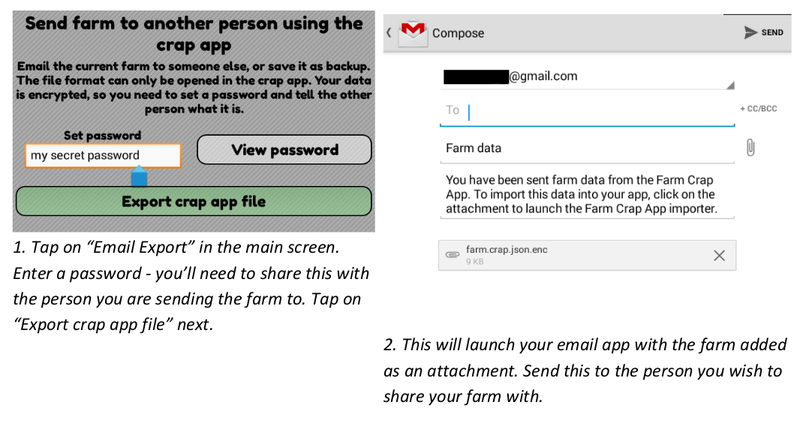
And the import is basically the same - tapping on the attachment takes you to an import screen that asks for a password, checks that the decryption worked and asks for confirmation that you want to import that farm's data:
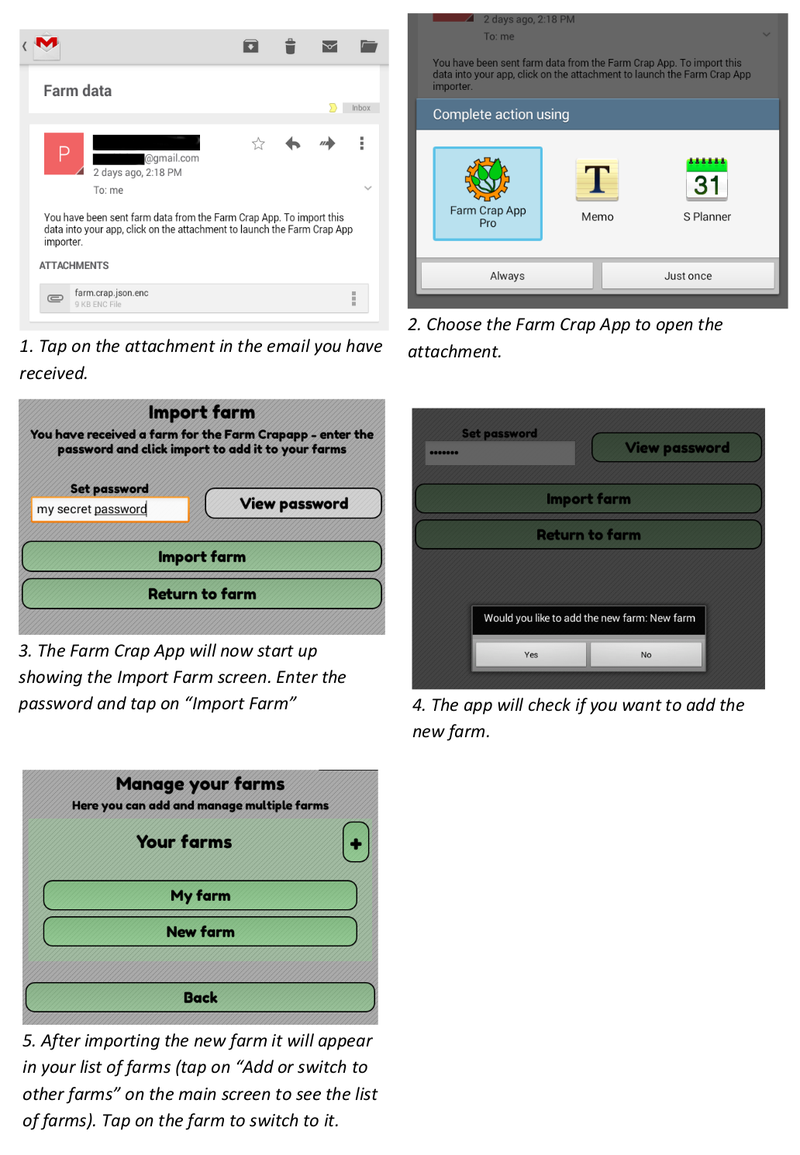
All too often, privacy is treated as a technical issue - when really it needs to be considered as part of the overall design process, consulting the people who have to use the software in the end. These decisions have important implications, for example we won't automatically have access to farm data in order to carry out research on manure use. Instead, if we want to do that we will need to ask people to help us by sending their data to us, turning a form of surveillance into an empowering citizen science activity that users are in ultimate control of. These issues affect people's lives in very tangible ways, and trust is increasingly becoming a major factor in whether technology is considered useful or not, so it's important that we get it right.
Created: 15 Jul 2021 / Updated: 15 Jul 2021
